SPACEx  :
Speech-driven Portrait Animation with Controllable Expression
:
Speech-driven Portrait Animation with Controllable Expression
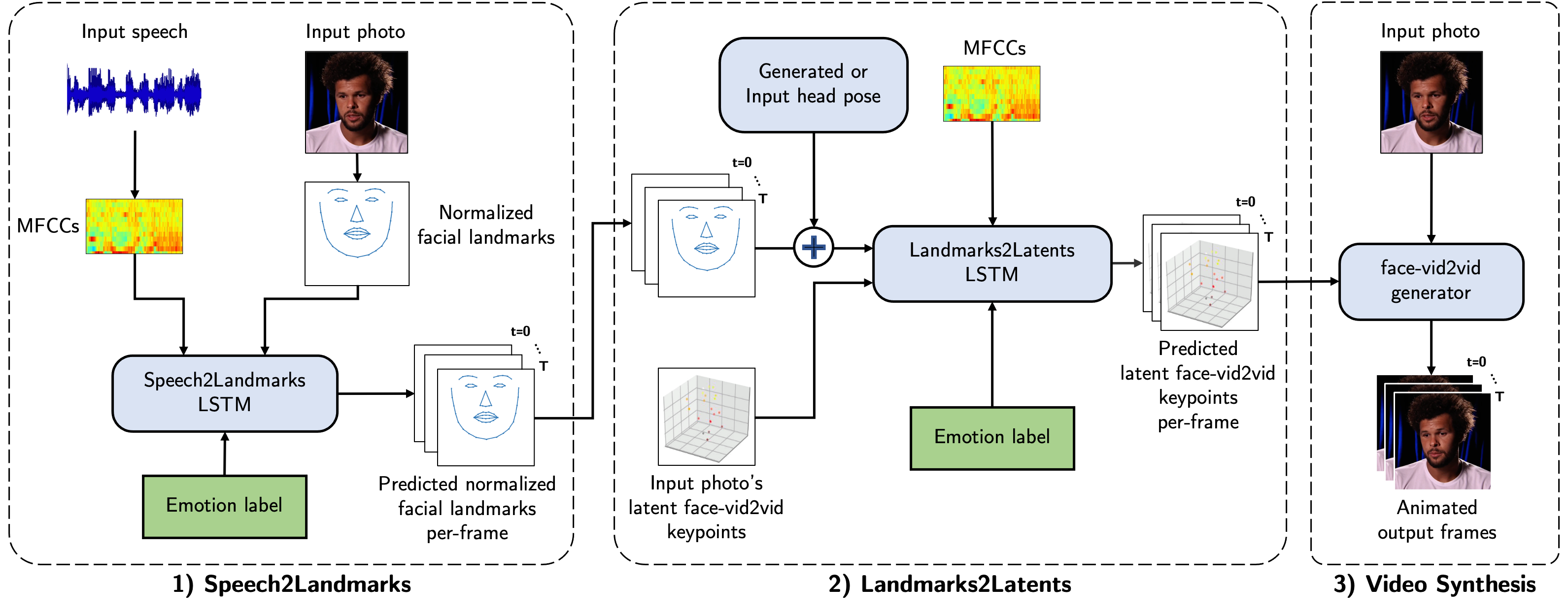
We present SPACEx, a method for generating high-resolution, expressive videos with realistic head pose, using just speech and a single image. It uses a multi-stage approach, combining the controllability of facial landmarks with the high-quality synthesis power of a pretrained face generator. SPACEx also allows for the control of emotions and their intensities. Our method outperforms prior methods in objective metrics for image quality and facial motions and is strongly preferred by users in pair-wise comparisons.
Speech-driven animation of a portrait, with control over the output pose, emotions, and intensities of expressions
| Pose | Generated | Transferred | Generated | Generated |
|---|---|---|---|---|
| Emotion | Neutral | Neutral | Happy | Surprise |
| Emotion | Neutral | Neutral | Sad | Fear |
| Pose | Generated | Transferred | Generated | Generated |